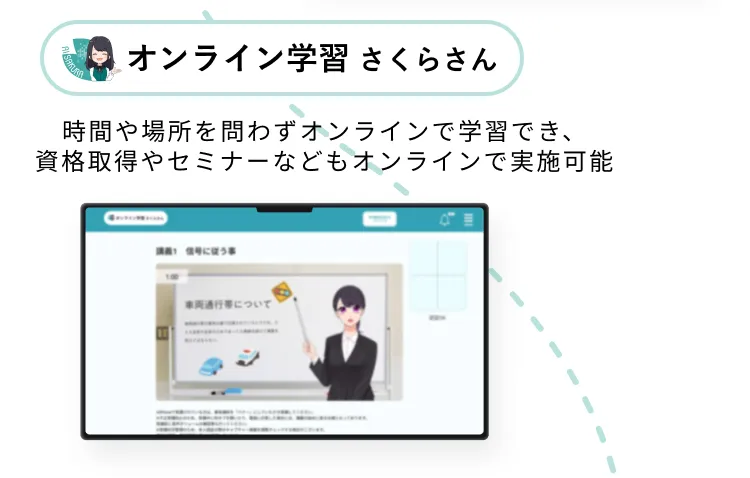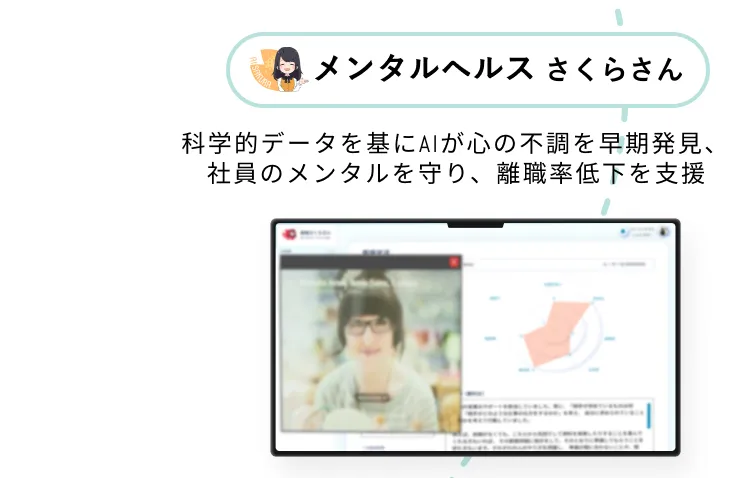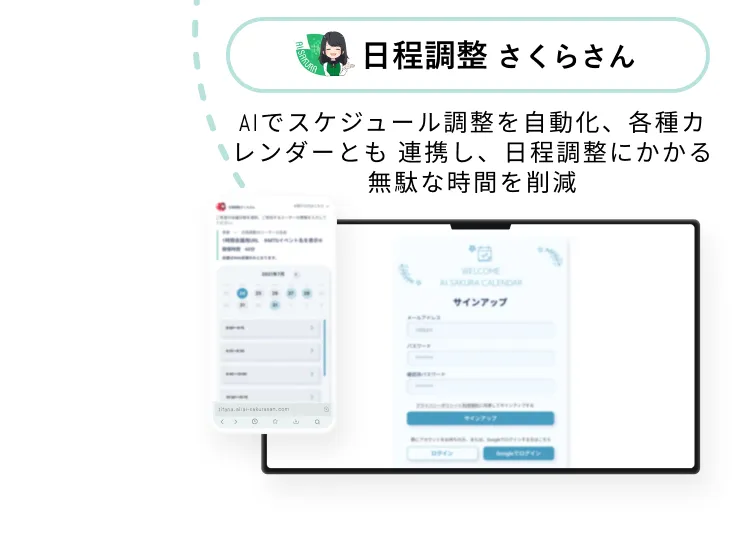




課題に合わせたAIサービスで
大手企業のDX推進を着実に実現!
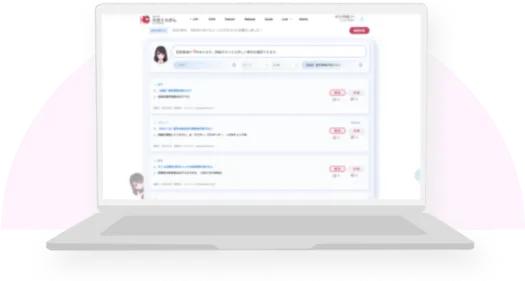
多くの大手企業が導入している
最新のAIチャットボット
自社従業員からの問い合わせ対応に
特化したAIチャットボット
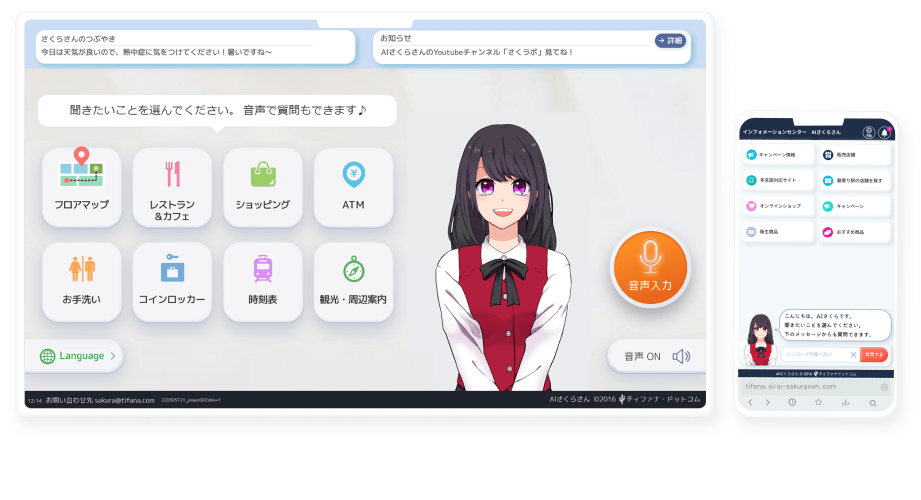
2016年から運用
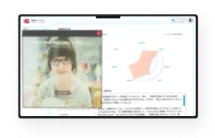
国内導入実績No.1のアバター接客

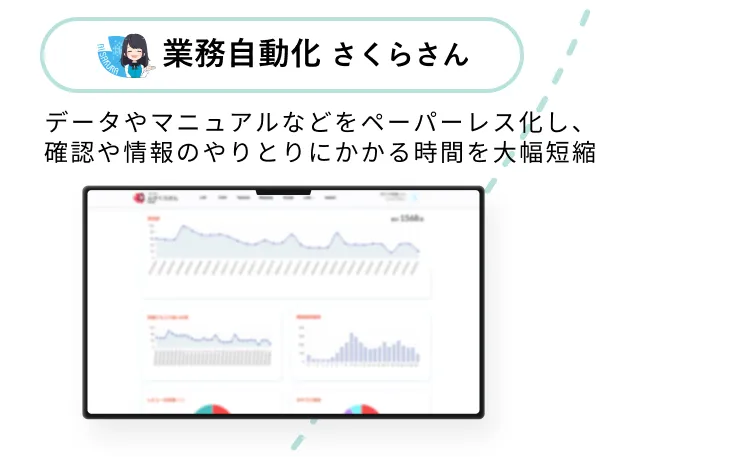
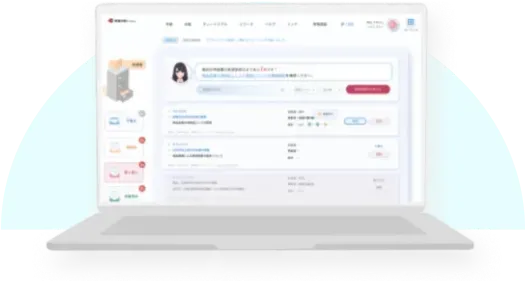
すべての申請・承認ワークフロー
をオンライン化
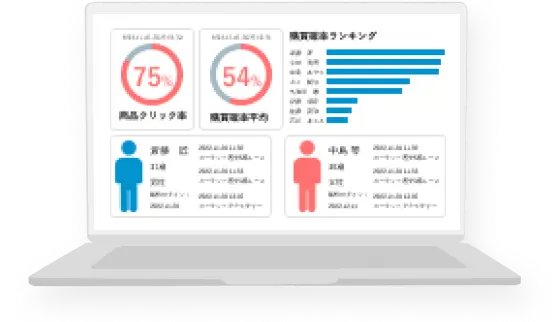
AI予測で、誰でも
簡単に需要予測やリスク回避
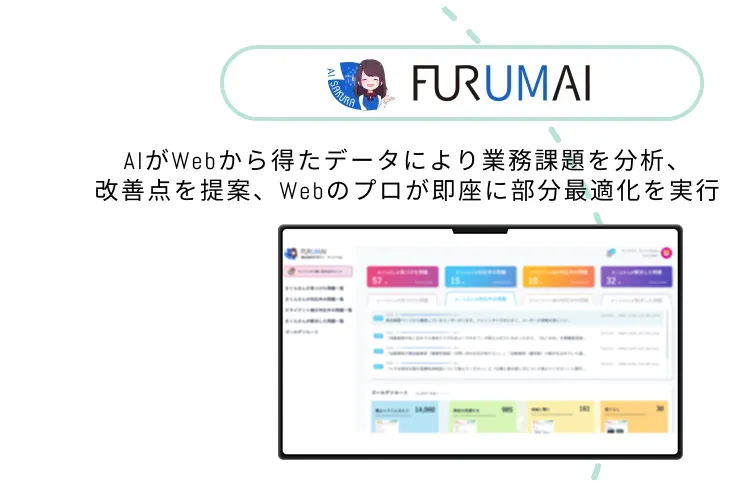
AIがWebサイトを自動で
解析し最適化
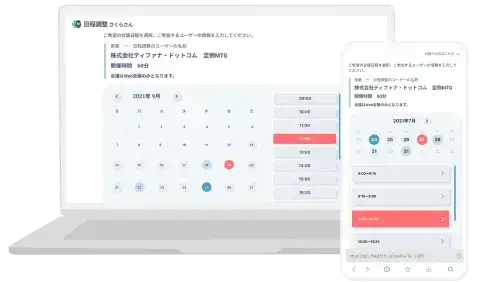
商談・会議など参加者との
スケジュール調整をAIが代行
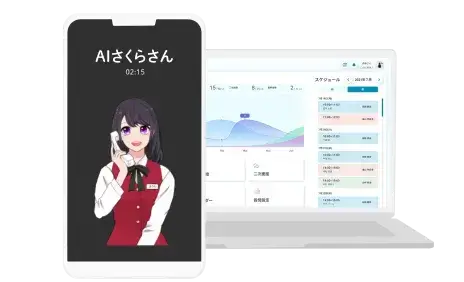
様々な電話対応業務を
AIが代行
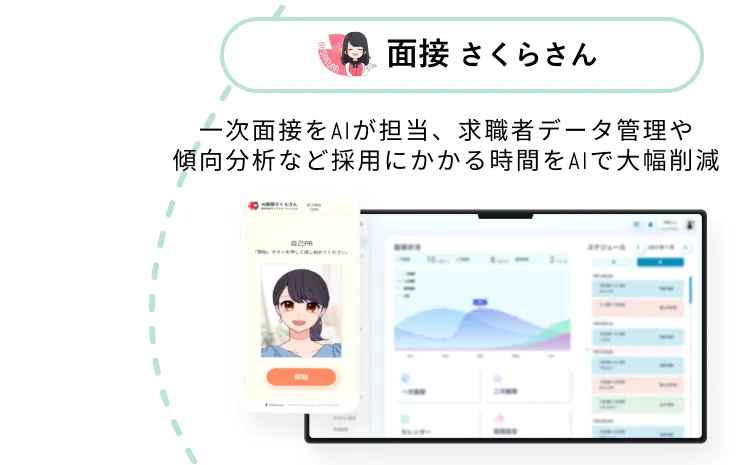
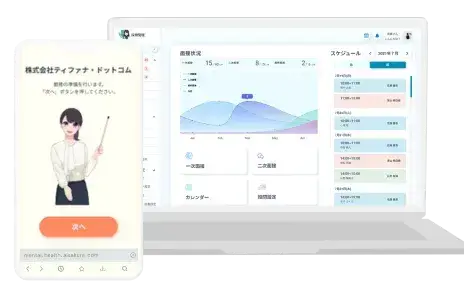
AIが面接やオーディション、
評価をサポート
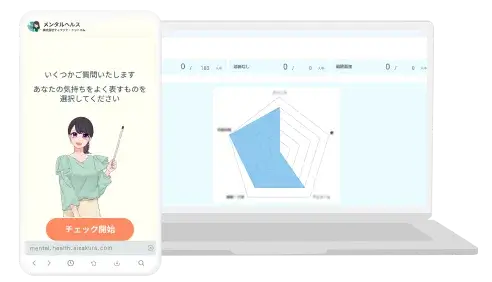
AIが従業員の心をケアし
離職率を低減
AIが人に代わって
落とし物問い合わせに対応
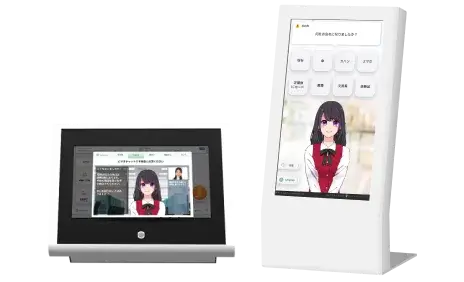

AIが人に代わって
受付対応を担当

多くの大手企業が導入している
最新のAIチャットボット

自社従業員からの問い合わせ対応に
特化したAIチャットボット
2016年から運用
国内導入実績No.1のアバター接客

すべての申請・承認ワークフローを
オンライン化
AI予測で、誰でも
簡単に需要予測やリスク回避
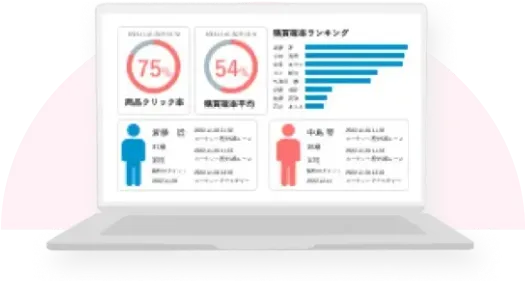
AIがWebサイトを自動で
解析し最適化
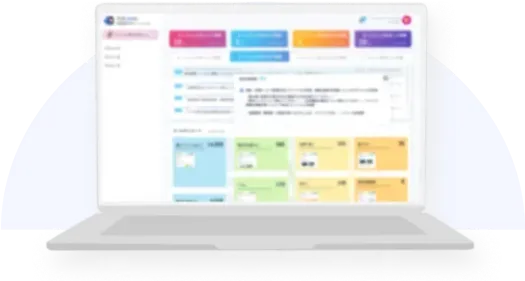
商談・会議など参加者との
スケジュール調整をAIが代行
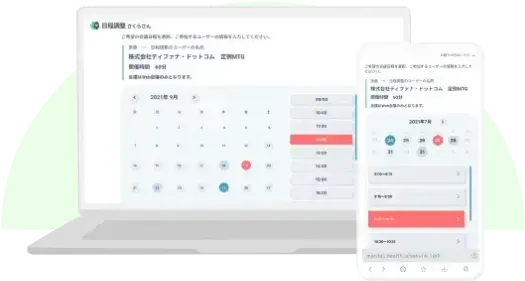
様々な電話対応業務を
AIが代行
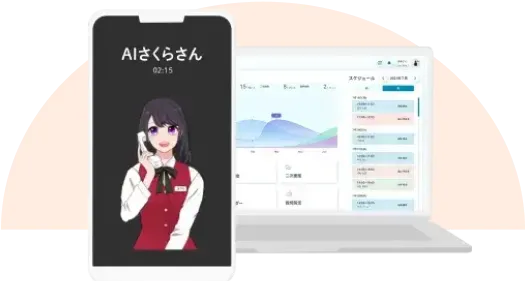
AIが面接やオーディション、
評価をサポート
AIが従業員の心をケアし
離職率を低減
AIが人に代わって
落とし物問い合わせに対応

AIが人に代わって
受付対応を担当